






集成一周年,Arm KleidiAI 与 XNNPack 实现无缝且透明性 AI 性能

本文转载自:Arm 社区

Arm社区
Arm与其生态系统的创新、深刻独到的行业与技术洞察、以及Arm全球社区的最新动态分享平台。
服务号
自 Arm® KleidiAI 首次集成到 XNNPack 已过去整整一年。KleidiAI 是一款高度优化的软件库,旨在加速 Arm CPU 上的人工智能 (AI) 推理。在过去一年中,从推出 INT4 矩阵乘法 (matmul) 优化以增强 Google Gemma 2 模型性能开始,到后续完成多项底层技术增强,Arm 在 XNNPack 上实现了显著的性能提升。
而更值得注意的是,开发者对此无需做任何改动。所有这些提升均实现了完全透明化,既不用修改代码,也无需额外的依赖项。只需像往常一样基于 XNNPack 构建并运行应用,就能自动享受到 Arm 通过 KleidiAI 引入的最新底层优化。本文就将为你详细介绍最新的增强功能。
- 面向 SDOT 和 i8mm 的 F32 x INT8 矩阵乘法
在先前 INT4 优化基础上,此次优化聚焦于通过动态量化加速 INT8 矩阵乘法,拓宽性能提升的覆盖范围,以支持各类 AI 模型。从卷积神经网络到前沿的生成式 AI 模型(例如 2025 年 5 月发布的 Stable Audio Open Small),这项优化带来了切实可见的性能提升。例如,该优化使扩散模块 (diffusion module) 的性能提升了 30% 以上。
与此前的 INT4 增强功能一样,INT8 优化借助 SDOT 指令和 i8mm 指令,在各类 CPU 上提升了动态量化性能。
- 面向 F32、F16 和 INT8 矩阵乘法的 SME2 优化
近期最令人振奋的进展之一,是 Armv9 架构上对可伸缩矩阵扩展 (SME2) 的支持。这为 F32 (Float32)、F16 (Float16) 和 INT8 矩阵乘法带来了显著的性能跃升,为新的高性能应用铺平道路。因此,无论是对于当前还是未来的 AI 工作负载,都能从一开始实现无缝加速,且无需任何额外投入。
SME2 是 Armv9-A CPU 架构中引入的一项全新 Arm 技术。SME2 基于可伸缩向量扩展 (SVE2) 技术构建,并通过可惠及 AI、计算机视觉、线性代数等多个领域的特性拓展了其应用范围。
SME2 的一项突出特性是矩阵外积累加 (Matrix Outer Product Accumulate, MOPA) 指令,该指令能够实现高效的外积运算。如下图所示,外积与点积的区别在于,点积的运算结果是一个标量,而外积则由两个输入向量生成一个矩阵。
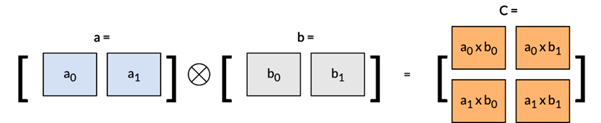
通过以下矩阵乘法示例来直观理解这一区别:
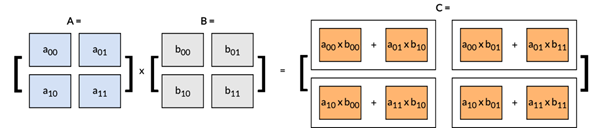
该矩阵乘法可分解为一系列外积运算,如下图所示:
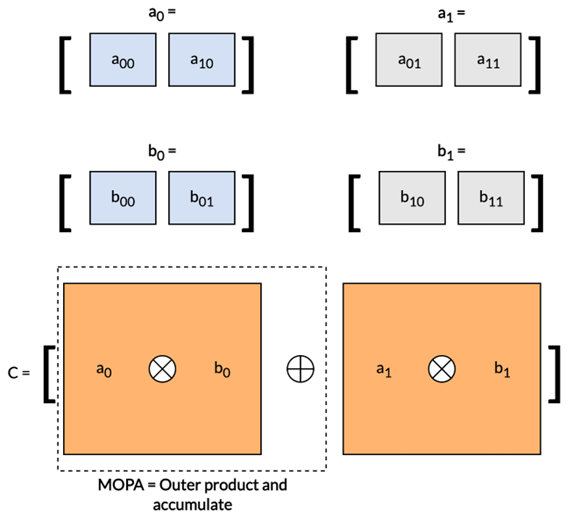
明确这一概念后,再来深入探讨构成优化的矩阵乘法例程核心的 SME2 汇编指令:
FMOPA za0.s, p0/m, p1/m, z1.s, z3.s
各操作数的含义如下:
FMOPA:浮点矩阵外积累加指令。
ZA0.s:用于存储和累积外积结果的 ZA 寄存器块。
p0/m 和 p1/m