






顶级大模型如满血671B的Deepseek R1/V3拥有开源模型最佳的智能和广泛的应用场景,然而,一些技术限制使得行业被动将模型质量按价格划分为三六九等:十几万价位只能用32B的模型,40多万可以开始70B,满血671Gb的模型则需要付出上百万才能体验到最好的模型质量和流畅对话。——而这恰恰是行云希望打破的。
凭借行云自研的推理引擎框架和对硬件的精准选型,我们让Deepseek 671B原版fp8的R1/V3模型能够在CPU DDR5内存为主的低成本硬件上以超过官网速度的体验运行,将“最强AI大脑”的门槛大幅降低至10万元价位,从今天开始每一个人都可以开始构建属于自己智能体。

创新技术
第一性原理分析模型需求,极致推理框架优化
高质量大模型对硬件的核心诉求是TB级的内存容量和显存级别的内存带宽,除了互联大量GPU之外,高端服务器CPU的DDR内存带宽已经越过了显存级别的临界点,完全可以满足大模型流畅运行的需求,成本却可以数量级降低。行云通过推理框架和算子的深度优化,实现了对模型推理过程的极致加速,充分打满硬件的内存带宽资源,推动模型推理性能逼近硬件理论极限。除此之外,行云还通过额外的消费级GPU卸载模型部分计算密集的部分,降低对于CPU算力的需求,进一步压低硬件成本,确保模型在足够低成本的硬件上实现20TPS+的流畅运行。
成本革命
10万元价位硬件支出的量级
在数周之前,当行云的推理框架第一次只使用双路CPU的DDR内存和一张游戏GPU将671B fp8的R1推理速度突破21TPS的时候,我们意识到它可以不再是一个玩具,而是成为可靠的工具。
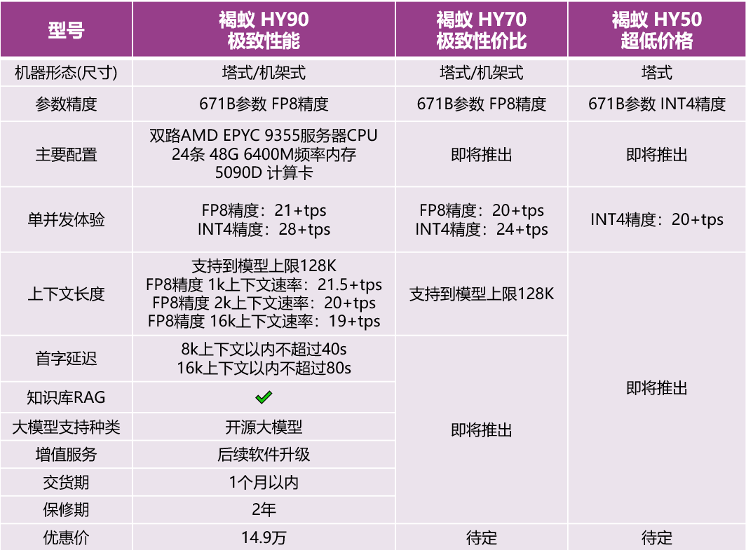
因此我们经过了方案筛选和稳定度验证,借助选型硬件+推理引擎框架,671B满血fp8的deepseek R1和v3模型可以在仅需10万元价位支出的设备上持续流畅运行。我们也希望为更多探索者增加信心——未来最好的大模型的硬件起步价将再也不会超过10万元。无论是初创团队还是大型企业,都能平权以更低的成本享受到顶级AI模型带来的红利,更低价位为AGI的创造者们带来了更大的想象力施展空间:未来能搭载最强模型的将会是一颗机器人的大脑、一台生产力工具PC甚至也可能是一个面对浅蓝色瓷砖打扫游泳池的小清洁机器人。
未来展望
加速迈向AGI时代
行云褐蚁一体机只是一个开始,我们也在开发多台一体机并发支持提升数十倍并发的软件软件框架以支撑更广场景的使用和低成本理念的验证。行云相信未来顶级大模型将在更多领域和场景中发挥作用,从智能家居到智慧城市,从医疗诊断到金融风控,触角将无处不在。因此行云也正在设计和制造我们的芯片产品,以进一步加速AI技术的低成本进程,行云的后续芯片产品将让云端和端侧的平均成本都先再下降一个数量级以上,并在未来持续迭代下降,从而让更多人享受到AI带来的便利和智能,实现AI普惠。如同刘慈欣小说中的褐蚁,渺小、微不足道的褐蚁,看似无法理解人类文明的意义,但仍然应该作为伟大时刻的见证者和参与者。行云的褐蚁大模型一体机产品同样希望秉承这一理念,让更多人真正参与到这场大模型的产业变革和升级中,实现AI普惠:宇宙公理的诞生,褐蚁星辰皆可见证。