
摩尔线程发布大模型训练仿真工具SimuMax v1.0:仿真精度显著提升,显存误差仅1%
近日,摩尔线程正式发布并开源大模型分布式训练仿真工具SimuMax 1.0版本。该版本在显存和性能仿真精度上实现突破性提升,同时引入多项关键功能,进一步增强了模型兼容性、灵活性与用户体验。
SimuMax是一款专为大语言模型(LLM)分布式训练负载设计的仿真模拟工具,可为单卡到万卡集群提供仿真支持。它无需实际执行完整训练过程,即可高精度模拟训练中的显存使用和性能表现,帮助用户深入洞察训练效率,探索提升计算效能的优化途径。 基于静态分析模型,摩尔线程自研的SimuMax通过结合成本模型、内存模型和屋顶模型,实现对训练过程的精准仿真。该工具支持多种主流分布式并行策略与优化技术,适用于以下多种应用场景: ▼ 并行策略:数据并行(DP)、张量并行(TP)、序列并行(SP)、流水线并行(PP)、专家并行(EP); ▼ 优化技术:ZeRO-1、完整重计算、选择性重计算、融合内核等; ▼ 适用对象:希望寻找最优训练策略以提升效率的用户;从事框架或大模型算法开发的工程师,用于优化与调试;芯片制造商,用于性能预测与硬件设计辅助。 核心突破: 仿真精度实现显著提升 SimuMax 1.0最显著的更新在于其仿真精度的大幅提升,为用户提供更可靠的分析结果。 ▼ 显存估计:针对Dense和MoE(混合专家)模型,显存估计误差稳定控制在1%以内; ▼ 性能估计:经测试,在多个主流GPU上,目前最优性能估计误差持续低于4%;
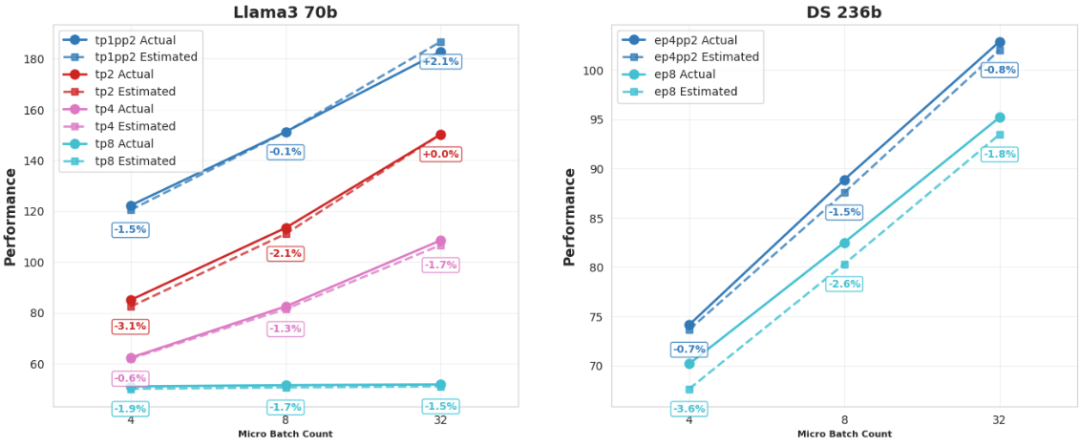
新功能与增强: 扩展模型兼容与精细化控制 SimuMax 1.0引入了多项新特性,支持更广泛的模型结构和高效率训练需求: ▼ MLA支持:新增对MLA模型架构的支持; ▼ 流水线并行(PP)增强:支持对首阶段和末阶段层的细粒度控制,优化模型分片策略; ▼ MoE灵活性提升:在混合专家(MoE)模型中支持自定义Dense层,为模型设计提供了更大的灵活性。 ▼ Megatron兼容:提供简化的模型迁移流程,可轻松转换和分析基于Megatron框架的模型,提升与现有生态的互操作性。 ▼ 重计算策略优化:实现更细粒度的选择性重计算,支持更精准的内存和计算资源权衡。 ▼ 全面的效率分析:新增对不同张量形状与内存布局下计算效率与利用率的评估功能。 快速开始 开发者可通过以下步骤,快速体验SimuMax: 克隆仓库:git clone git@github.com:MooreThreads/SimuMax.gitcd SimuMax
安装Python包:
运行示例: 参考项目中的教程和示例(如examples/perf_llama3_8b_tp1_pp2.py),即可开始使用SimuMax进行训练仿真。 持续优化与生态共建 SimuMax已在GitHub全面开源,开发者可访问仓库获取源代码、详细文档和示例。摩尔线程鼓励开发者通过提交Issue报告问题或通过Pull Request贡献代码,共同促进SimuMax功能的完善和软件生态的繁荣。 ▼ SimuMax 开源地址: https://github.com/MooreThreads/SimuMax 摩尔线程始终致力于为开发者提供强大的软件工具链。SimuMax的发布,将为大模型分布式训练的仿真和优化提供精准视角,助力AI产业提升算力利用效率,探索更高效的训练范式。 未来,摩尔线程SimuMax团队将继续积极开发,计划增加对上下文并行、更多流水线调度器、通算并行、Offload技术、策略搜索以及更精准的memory- bound算子模拟等功能的支持。 ▼ 关于摩尔线程 摩尔线程以全功能GPU为核心,致力于向全球提供加速计算的基础设施和一站式解决方案,为各行各业的数智化转型提供强大的AI计算支持。 我们的目标是成为具备国际竞争力的GPU领军企业,为融合人工智能和数字孪生的数智世界打造先进的加速计算平台。我们的愿景是为美好世界加速。pip install -r requirements.txtpip install -v -e .